Black-Box Explanation of Object Detectors via Saliency Maps (D-RISE)
Boston University & Adobe Research
Abstract
We propose D-RISE, a method for generating visual explanations for the predictions of object detectors. Utilizing the proposed similarity metric that accounts for both localization and categorization aspects of object detection allows our method to produce saliency maps that show image areas that most affect the prediction. D-RISE can be considered "black-box" in the software testing sense, as it only needs access to the inputs and outputs of an object detector. Compared to gradient-based methods, D-RISE is more general and agnostic to the particular type of object detector being tested and does not need knowledge of the inner workings of the model. We show that D-RISE can be easily applied to different object detectors including one-stage detectors such as YOLOv3 and two-stage detectors such as Faster-RCNN. We present a detailed analysis of the generated visual explanations to highlight the utilization of context and possible biases learned by object detectors.
Method
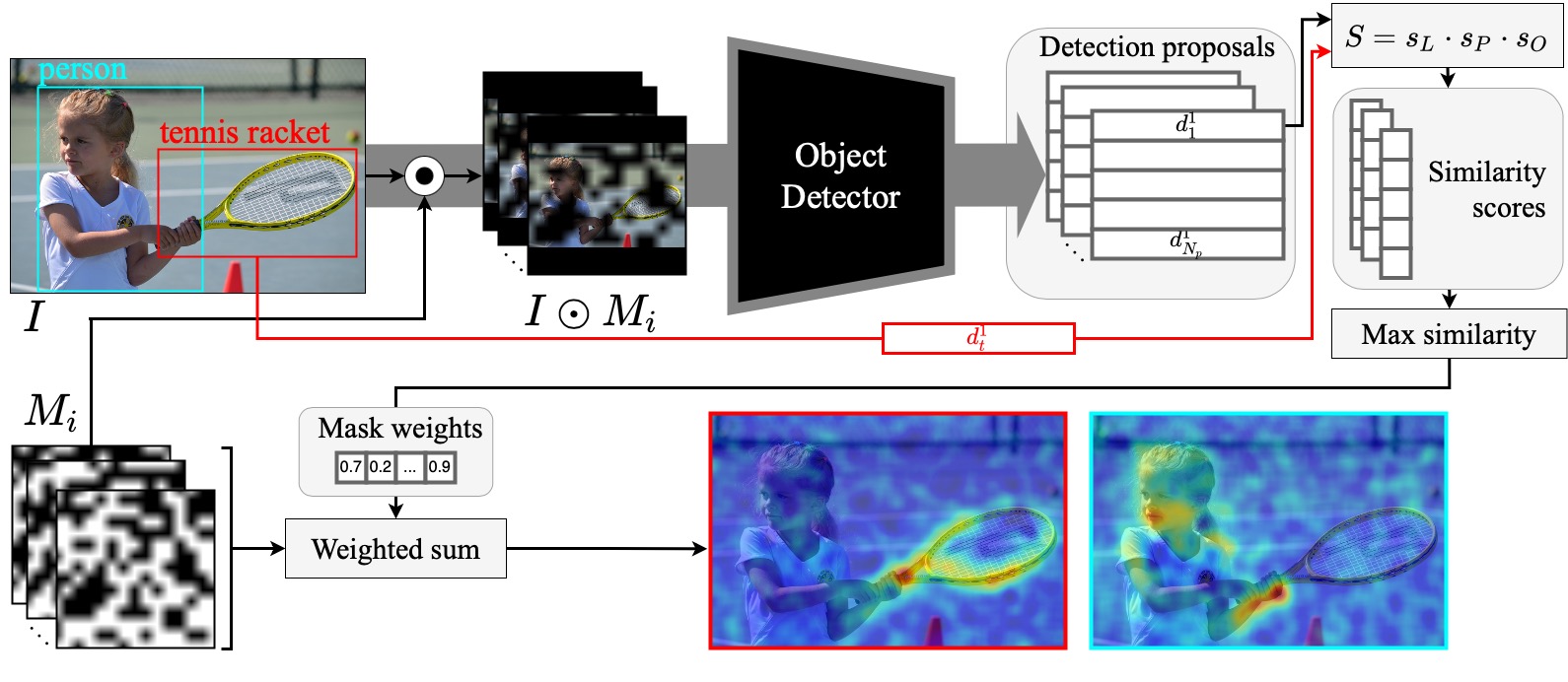
D-RISE extends the RISE framework to object detectors by defining a similarity metric that jointly captures localization (IoU with the predicted bounding box) and categorization (class score) aspects of a detection. Given a black-box detector, D-RISE probes it with randomly masked versions of the input image and computes a weighted sum of the masks, where weights are determined by how similar each masked detection is to the original prediction.
This design makes D-RISE model-agnostic: it works with any detector architecture — including one-stage models like YOLOv3 and two-stage models like Faster-RCNN — without requiring access to gradients or internal activations.
Presentation (CVPR 2021)
Slides
BibTeX
@inproceedings{Petsiuk2021drise,
author = {Vitali Petsiuk and
Rajiv Jain and
Varun Manjunatha and
Vlad I. Morariu and
Ashutosh Mehra and
Vicente Ordonez and
Kate Saenko},
title = {Black-Box Explanation of Object Detectors via Saliency Maps},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}