GoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining
AI Center — Mountain View, Samsung Electronics
* Equal contribution, order chosen randomly.
† Work done while at Samsung Electronics.
Abstract
Until recently, the success of large-scale vision-language models (VLMs) has primarily relied on billion-sample datasets, posing a significant barrier to progress. Latest works have begun to close this gap by improving supervision quality, but each addresses only a subset of the weaknesses in contrastive pretraining. We present GoldiCLIP, a framework built on a Goldilocks principle of finding the right balance of supervision signals. Our multifaceted training framework synergistically combines three key innovations: (1) a text-conditioned self-distillation method to align both text-agnostic and text-conditioned features; (2) an encoder integrated decoder with Visual Question Answering (VQA) objective that enables the encoder to generalize beyond the caption-like queries; and (3) an uncertainty-based weighting mechanism that automatically balances all heterogeneous losses. Trained on just 30 million images, 300x less data than leading methods, GoldiCLIP achieves state-of-the-art among data-efficient approaches, improving over the best comparable baseline by 2.2 points on MSCOCO retrieval, 2.0 on fine-grained retrieval, and 5.9 on question-based retrieval, while remaining competitive with billion-scale models.
Method
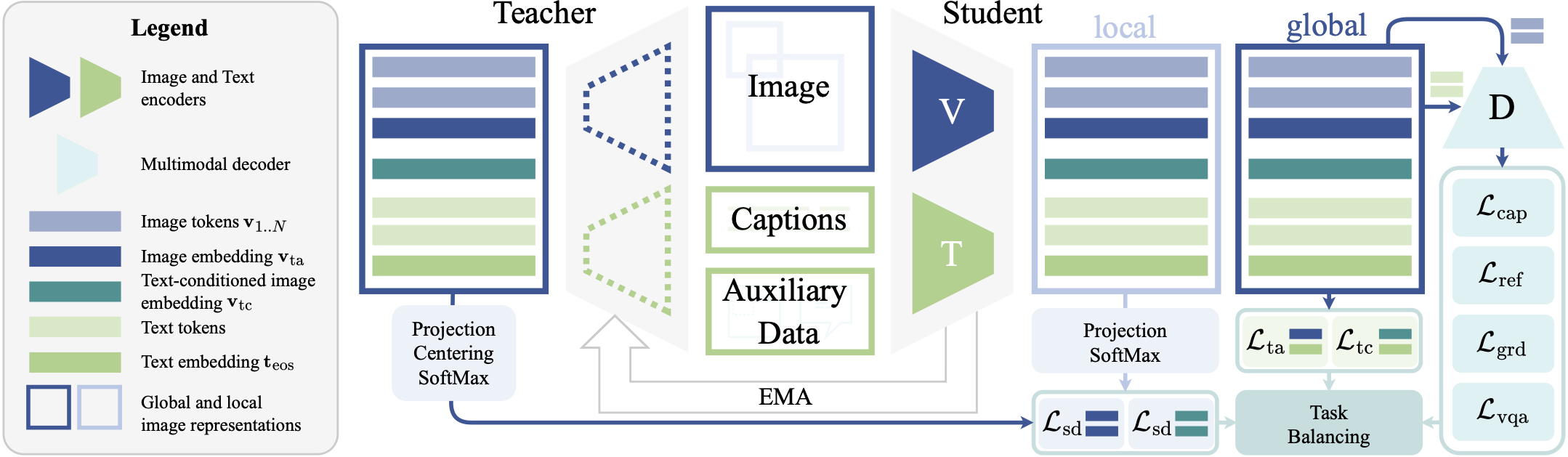
GoldiCLIP is a unified training framework that systematically integrates diverse supervision signals to dramatically improve data efficiency in vision-language pre-training. Our framework has three key components:
- Text-Conditioned Self-Distillation: A novel self-distillation method that extends to both text-conditioned and text-agnostic representations, improving local-to-global consistency to enhance vision encoder performance.
- Decoder Objectives with VQA: Incorporates a transformer-based decoder that autoregressively generates text sequences conditioned on visual features. By integrating a Visual Question Answering (VQA) objective, the model learns a more robust feature space encoding object identities, attributes, and spatial relationships.
- Task Balancing: Optimizes the model using a diverse set of six supervisory signals via uncertainty-based multi-task learning, eliminating the need for expensive hyperparameter tuning while avoiding training collapse.
Results
Trained on just 30 million images, GoldiCLIP achieves state-of-the-art performance among data-efficient approaches. Our evaluation demonstrates significant improvements over existing models (such as FLAIR) across diverse benchmarks including:
- Zero-Shot Retrieval: Superior performance on MSCOCO and Flickr30k.
- Fine-Grained Retrieval: Exceptional granular understanding on challenging datasets like DOCCI-FG and IIW-FG.
- Zero-Shot Semantic Segmentation: Outperforms all models trained on comparable datasets by capturing nuanced spatial representations.
| Method | Data Size | MSCOCO | Flickr30k | DOCCI-FG | ||
|---|---|---|---|---|---|---|
| T2I (R@1) | I2T (R@1) | T2I (R@1) | I2T (R@1) | T2I (R@1) | ||
| DreamLIP | 30M | 44.8 | 62.3 | 73.3 | 89.9 | 21.6 |
| COSMOS | 30M | 52.5 | 68.0 | 80.3 | 92.9 | 23.1 |
| FLAIR | 30M | 53.3 | 68.0 | 81.1 | 94.7 | 25.0 |
| SigLIP 2 | 10B | 52.5 | 70.0 | 80.0 | 91.8 | 23.2 |
| GoldiCLIP (Ours) | 30M | 55.5 | 70.3 | 83.0 | 94.8 | 27.0 |
BibTeX
@article{mohan2026goldiclip,
title={GoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining},
author={Mohan, Deen Dayal and Souri, Hossein and Petsiuk, Vitali and Min, Juhong and Sharma, Gopal and Zhou, Luowei and Kumar, Suren},
journal={arXiv preprint},
year={2024}
}